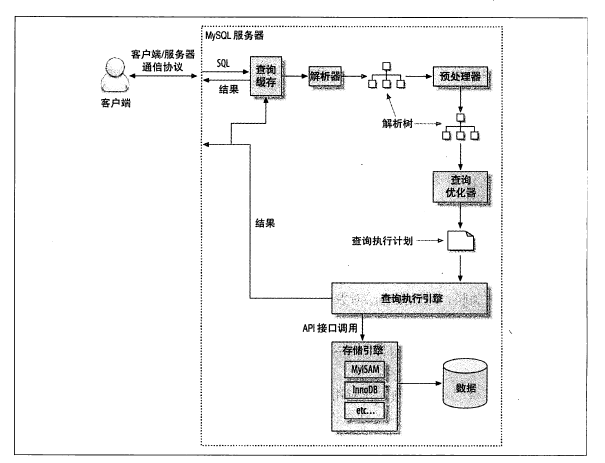
WAL即 Write Ahead Log,WAL的主要意思是说在将元数据的变更操作写入磁盘之前,先预先写入到一个log文件中。为什么要先写日志文件呢,我们一步一步的来探索。
基础数据了解
首先,我们需要了解一下几个数据。
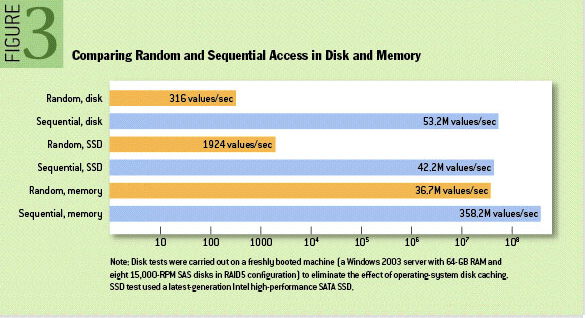
从上图可以看出两点:
- 内存的读写速度比随机读写磁盘高出几个数量级。
- 磁盘顺序读写效率堪比内存
数据写入磁盘过程
那用户进程是怎么把数据写入磁盘的呢?我们来看下Redis之父Antires是怎么说的:
1: The client sends a write command to the database (data is in client’s memory).
2: The database receives the write (data is in server’s memory).
3: The database calls the system call that writes the data on disk (data is in the kernel’s buffer).
4: The operating system transfers the write buffer to the disk controller (data is in the disk cache).
5: The disk controller actually writes the data into a physical media (a magnetic disk, a Nand chip, …).
翻译如下:
- 客户端向数据库发送写命令。
- 数据库收到写命令。
- 数据库通过系统调用将数据写入内核缓冲区(page cache)。
- 操作系统将缓冲区数据传输至磁盘控制器,暂存在磁盘缓冲区。
- 磁盘控制器将数据精准的写入物理磁盘。
我们考虑如下异常情况:
异常处理
1、数据库挂了
如果只是数据库挂了,这时候其实操作系统是正常工作的,
只有当第3步完成之后,才能保证数据安全写入。因为剩下的都可以由操作系统来完成。
2、机器断电
机器断电之后,数据库、操作系统、磁盘均不能正常工作。只有完成这5步才算真正的写入磁盘。
WAL原理
- 通过cache合并多条写操作为一条,减少IO次数
- 日志顺序追加性能远高于数据随机写。
WAL的应用
MySQL WAL应用
MySQL通过redolog、undolog实现事务的原子性和持久化。Hbase WAL应用