MySQL分库分表是大厂常见的技术方案。
为什么要做分库分表呢?
- 分库有利于服务隔离与解耦,方便单独扩容和故障恢复。
- 分表可以解决大表的运维难题,提高并发性能。
分库大家比较容易理解,一般随着业务粒度的划分进行。
而分表的形式和用途多种多样,同样达到的目的和效果也各不相同。
常见的解决大表问题的方案是水平分表。本文重点介绍水平分表的方案以及扩容方式。
常见水平分表方式
连续分片
根据特定字段(比如用户ID、订单时间)的范围,值在该区间的,划分到特定节点。
优点:集群扩容后,指定新的范围落在新节点即可,无需进行数据迁移。
缺点:如果按时间划分,数据热点分布不均(历史数冷当前数据热),导致节点负荷不均。
ID取模分片
一致性Hash算法
Snowflake 分片
Snowflake 是 Twitter 开源的分布式 ID 生成算法,其结果为 long(64bit) 的数值。
其特性是各节点无需协调、按时间大致有序、且整个集群各节点单不重复。
该数值的默认组成如下(符号位之外的三部分允许个性化调整):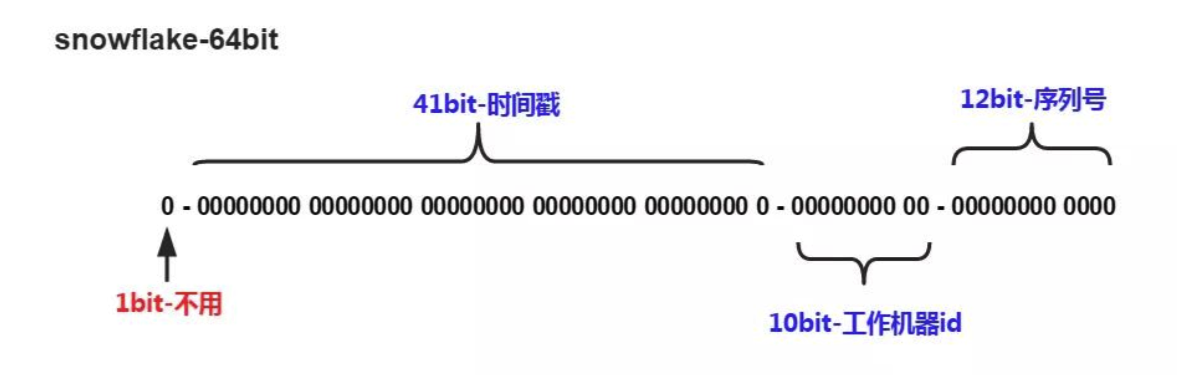
分表多维度查询
比如,有一张订单表,订单表有100个字段,常用查询方式有两种:
- 根据用户id查所有的订单
- 根据商品id查所有的订单
- 根据订单id查询订单详情
如果根据用户ID取模的方式分表,这时候根据商品id查询数据可能会落在多个分表上。
同理,如果根据商品ID取模的方式分表,这时候根据用户id查询数据可能会落在多个分表上。
Mysql方案
把数据冗余两份,分别按用户id、商品id、订单来做分表,以空间换时间。
适合数据量可控,查询纬度最多两个且固定的业务。
构建宽表,使用Elasticsearch
ElasticSearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。
充分利用ElasticSearch的水平伸缩性,能使数据在生产环境变得更有价值分表扩容
对于快速发展的业务来说,经常会遇到这样的问题,在设计分表的时候,数据量预估不准确,导致分表数量不够,后期需要扩容。
当然,扩容的要求是尽量少的数据迁移和改造。
常规方案
如果增加的节点数和扩容操作没有规划,那么绝大部分数据所属的分片都有变化,需要在分片间迁移:
- 预估迁移耗时,发布停服公告;
- 停服(用户无法使用服务),使用事先准备的迁移脚本,进行数据迁移;
- 修改为新的分片规则;
- 启动服务器。
免迁移扩容原理
- 单表架构
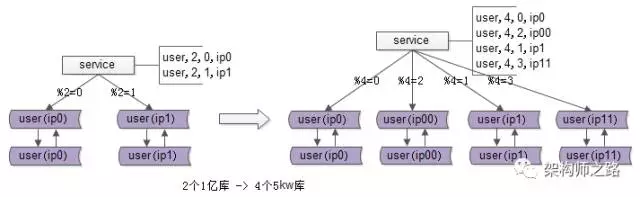
采用双倍扩容策略,避免数据迁移。
扩容前每个节点的数据,有一半要迁移至一个新增节点中,对应关系比较简单。
具体操作如下(假设已有 2 个节点 A/B,要双倍扩容至 A/A2/B/B2 这 4 个节点):
无需停止应用服务器;
新增两个数据库 A2/B2 作为从库,设置主从同步关系为:A=>A2、B=>B2,直至主从数据同步完毕(早期数据可手工同步);
调整分片规则并使之生效:
- 原 ID%2=0 => A 改为 ID%4=0 => A, ID%4=2 => A2;
- 原 ID%2=1 => B 改为 ID%4=1 => B, ID%4=3 => B2。
解除数据库实例的主从同步关系,并使之生效;
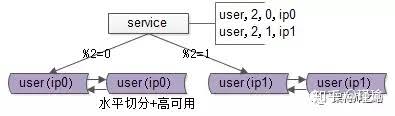
此时,四个节点的数据都已完整,只是有冗余(多存了和自己配对的节点的那部分数据),择机清除即可(过后随时进行,不影响业务)。
免迁移扩容实施步骤
1 修改配置
主要修改两处:
a)数据库实例所在的机器做双虚ip,原来%2=0的库是虚ip0,现在增加一个虚ip00,%2=1的另一个库同理
b)修改服务的配置(不管是在配置文件里,还是在配置中心),将2个库的数据库配置,改为4个库的数据库配置,修改的时候要注意旧库与辛苦的映射关系:
%2=0的库,会变为%4=0与%4=2;
%2=1的部分,会变为%4=1与%4=3;这样修改是为了保证,拆分后依然能够路由到正确的数据。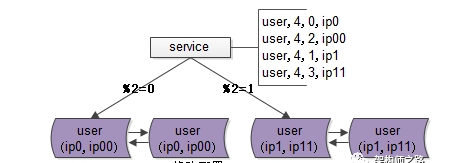
2 reload配置,实例扩容
服务层reload配置,reload可能是这么几种方式:
a)比较原始的,重启服务,读新的配置文件
b)高级一点的,配置中心给服务发信号,重读配置文件,重新初始化数据库连接池不管哪种方式,reload之后,数据库的实例扩容就完成了,原来是2个数据库实例提供服务,现在变为4个数据库实例提供服务,这个过程一般可以在秒级完成。
整个过程可以逐步重启,对服务的正确性和可用性完全没有影响:
a)即使%2寻库和%4寻库同时存在,也不影响数据的正确性,因为此时仍然是双主数据同步的
b)服务reload之前是不对外提供服务的,冗余的服务能够保证高可用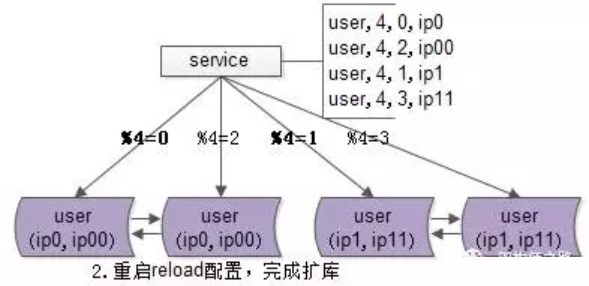
完成了实例的扩展,会发现每个数据库的数据量依然没有下降,所以第三个步骤还要做一些收尾工作。
3 收尾工作,数据收缩
有这些一些收尾工作:
a)把双虚ip修改回单虚ip
b)解除旧的双主同步,让成对库的数据不再同步增加
c)增加新的双主同步,保证高可用
d)删除掉冗余数据,例如:ip0里%4=2的数据全部干掉,只为%4=0的数据提供服务啦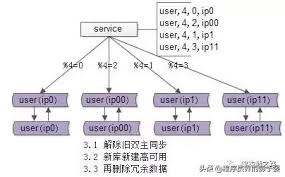
这样下来,每个库的数据量就降为原来的一半,数据收缩完成。
总结
该帅气方案能够实现n库扩2n库的秒级、平滑扩容,增加数据库服务能力,降低单库一半的数据量,其核心原理是:成倍扩容,避免数据迁移。
迁移步骤:
(1)修改配置
(2)reload配置,实例扩容完成
(3)删除冗余数据等收尾工作,数据量收缩完成